Michelle Kaffenberger
Blavatnik School of Government, University of Oxford
Blog

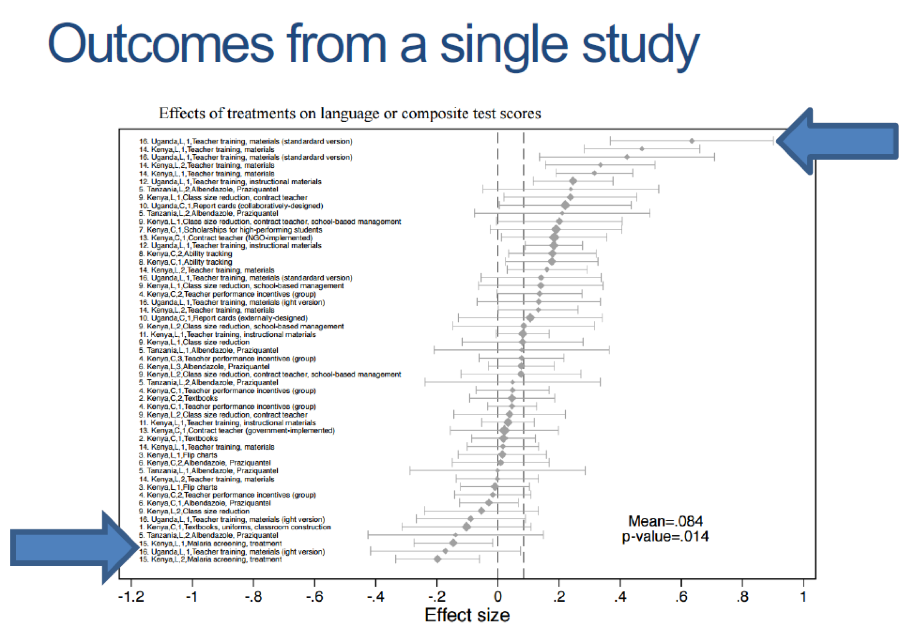
A paper presented by Rebecca Thornton in the opening panel of the RISE Annual Conference illustrates extreme sensitivity of program impact to design and implementation. The researchers did a RCT that estimated two treatment arms in the same area of Uganda that were two versions of a “teacher training” literacy program. The two versions, which seemed largely similar with one version modified as little as possible in order to be less costly, had wildly different results. In fact, the results from the “same” program in the same place span the entire range of impacts from a systematic review of 50 education interventions (Figure 1): one version of the program is the top performer in learning effect sizes, the other version is second-to-last. This suggests that in addition to concern about “external validity” of the evidence from impact evaluations—whether what worked “here” will work “there”—there is also a concern about “construct validity”—if even in the same place and time two variants of the same “teacher training” program had radically different impacts what does it mean to lump together findings about “teaching training” programs at all?
Figure 1. Results from two versions of one program span a systematic review
Limitations to a “scale what works” approach
When governments consider implementing or scaling a program that has been evaluated by a RCT, they typically must adapt it for their local context, fiscal constraints, teacher capacity, and organizational capability. This raises two questions. First, the commonly-discussed question of external validity—will the results of exactly the same project (if that is even feasible) hold when implemented in a different context? The second, less-commonly-discussed, but just as important, question of constructvalidity—do we have an adequate intellectual construct of what “the same” project is? Will the results hold when the program is constructedin the design space a different way or implemented with more or less fidelity? By analogy to medicine, the external validity question is whether exactly the same molecule (in chemical composition and structure) will have the same impact on men and women, while the construct validity question is whether we can specify precisely enough what constitutes the treatment.
There is reason to believe construct validity matters a lot. Systematic reviews show that variance around estimated impacts of programs within the sameclassof intervention is enormous. For example, a systematic review by McEwan (2015) found that “ICT” interventions had a mean effect size on learning of 0.15, but within the class of ICT interventions, effect sizes ranged from positive 0.32 to negative 0.58—suggesting that knowing the mean ICT effect size tells you very little about the effectiveness of any particular ICT program (and two of the extremes in this review were also seemingly minor variants on the same program in the same place—so this variation was not completely due to “external” validity). In another example, Bold et al. find that while contract teaching in Kenya was effective when implemented by an NGO (both in an original assessment and when scaled), when delivered and scaled by the government (e.g., with different implementation and political economy constraints, accountability, and incentive structures, etc.) it had no significant impacts. This similarly suggests wide variation within a class of “contract teaching” interventions and “who implements” is itself a key part of design.
An example of teacher training
Thornton and Kerwin addressed this issue head-on by implementing two versions of the same program in the same context, so the only difference was the specific design. They evaluated what they called the “standard” version of the Mango Tree Literacy Program, which included training first- to third-grade teachers in a mother-tongue-first pedagogical strategy; material inputs including readers and primers for students, a teacher’s guide with scripted lessons, classroom clocks, and writing slates; and support for teachers including residential training and monthly classroom visits delivered by program staff.
The standard program was too expensive to be scaled by the local government, though, so the researchers also evaluated a lower-cost version, modified in a way that “explicitly emulated” what the government might consider scaling. This version changed three elements: 1) removed the most expensive inputs (clocks and slates), 2) used a cascade model to deliver training, and 3) conducted fewer support visits. The modifications were considered “relatively small” based on a standardized set of indicators for comparing teacher training programs.
The standard program yielded impressive results, improving student letter recognition 1.01 standard deviations, and overall reading by 0.64 standard deviations. It also improved the ability to write one’s first name by 1.31 standard deviations, last name by 0.92 standard deviations, and overall writing ability by 0.45 standard deviations. These results put it at the top of a systematic review of education interventions.
The low-cost program, however, produced qualitatively different results. Improvements in letter recognition was lower, at 0.41 standard deviations, and gains in overall reading were small and statistically insignificant. Gains in basic writing ability were similarly smaller, with 0.45 standard deviation improvement in the ability to write one’s first name, and there were large, statistically-significant negativeimpacts on some writing components such as writing a sentence (-0.3 standard deviations).
Figure 2. The full-cost and reduced-cost versions of the program have qualitatively different results
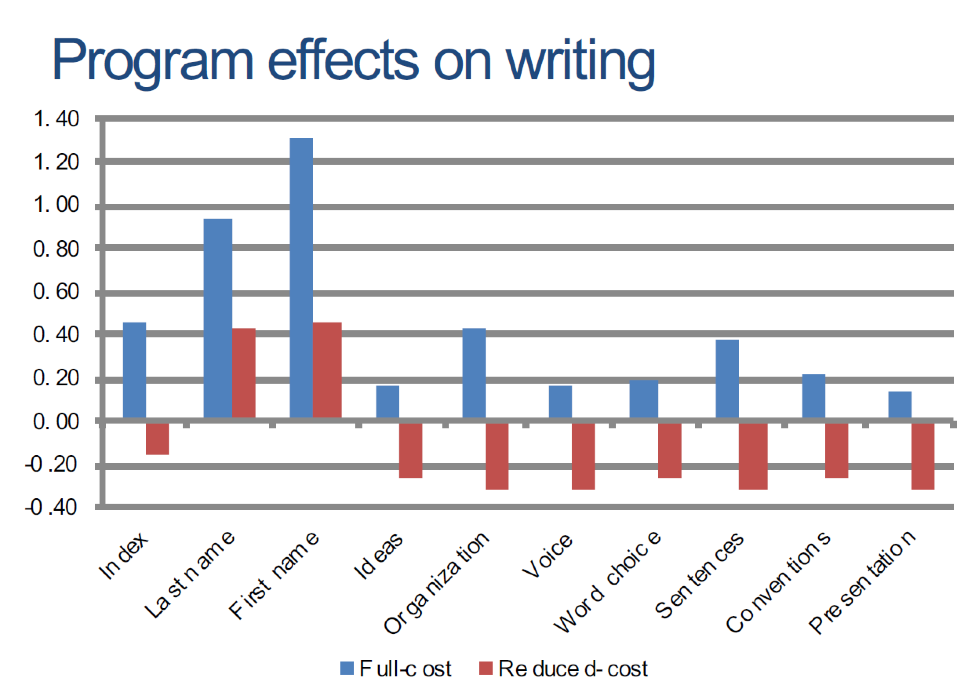
The results suggest that effectiveness is highly sensitive to even small changes in the construct of the program.
Crawling the design space
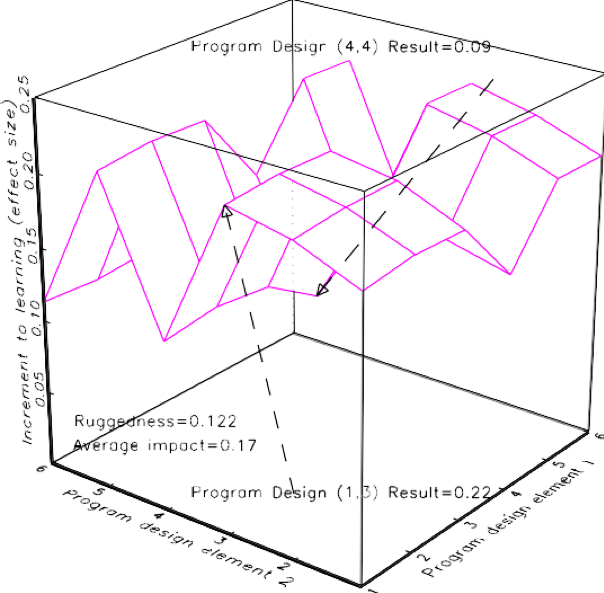
While the Mango Tree evaluation compared two versions of the program, thousands of versions are possible—and it would be impossible to evaluate them all. All these combinations of design elements represent the “design space”, and as Lant Pritchett showed in an earlier RISE Insight note, each point in the design space is associated with a different outcome which, put together, produce a “response surface.” (See Figure 3 for a visualization of a response surface for a program with only two design elements and six options for each.) A design in which all the elements work together to produce positive outcomes would be on a high point of the response surface, while a combination that, for example, cuts important elements would be on a low point.
Figure 3. A Rugged Response Surface with (only) two design elements and six options each
Rather than trying to run separate evaluations for each point in the design space (which for most programs would be impossible anyway) an alternative is to “crawl the design space”—in which the program iterates and adapts as it goes. With rapid feedback from robust data collection, a program can identify what is working and adjust what isn’t, to find those higher points on the response surface. Simulations by Nadel and Pritchett show that crawling the design space can produce better outcomes than a RCT-based learning strategy, and the Problem DrivenIterative Adaptation (PDIA) approach is built around the need for organizations to learn and adapt as they go.
Thornton’s paper illustrates perfectly the perils of considering only one point in the design space (or even five or ten points, for programs where there could be a thousand design combinations) and taking that as evidence of “what works” and what doesn’t. It highlights the importance of research that looks at the system, the context, and the details of a program, and the importance of building systems for learning that themselves can learn and adapt as they go.
RISE blog posts and podcasts reflect the views of the authors and do not necessarily represent the views of the organisation or our funders.